Today I started wondering, how could you move an existing Amazon Web Services machine to a bigger instance without having to recreate the machine. For example, moving from a t1.micro to m1.small.
With the help of the command line tools, it’s a fairly simply process.
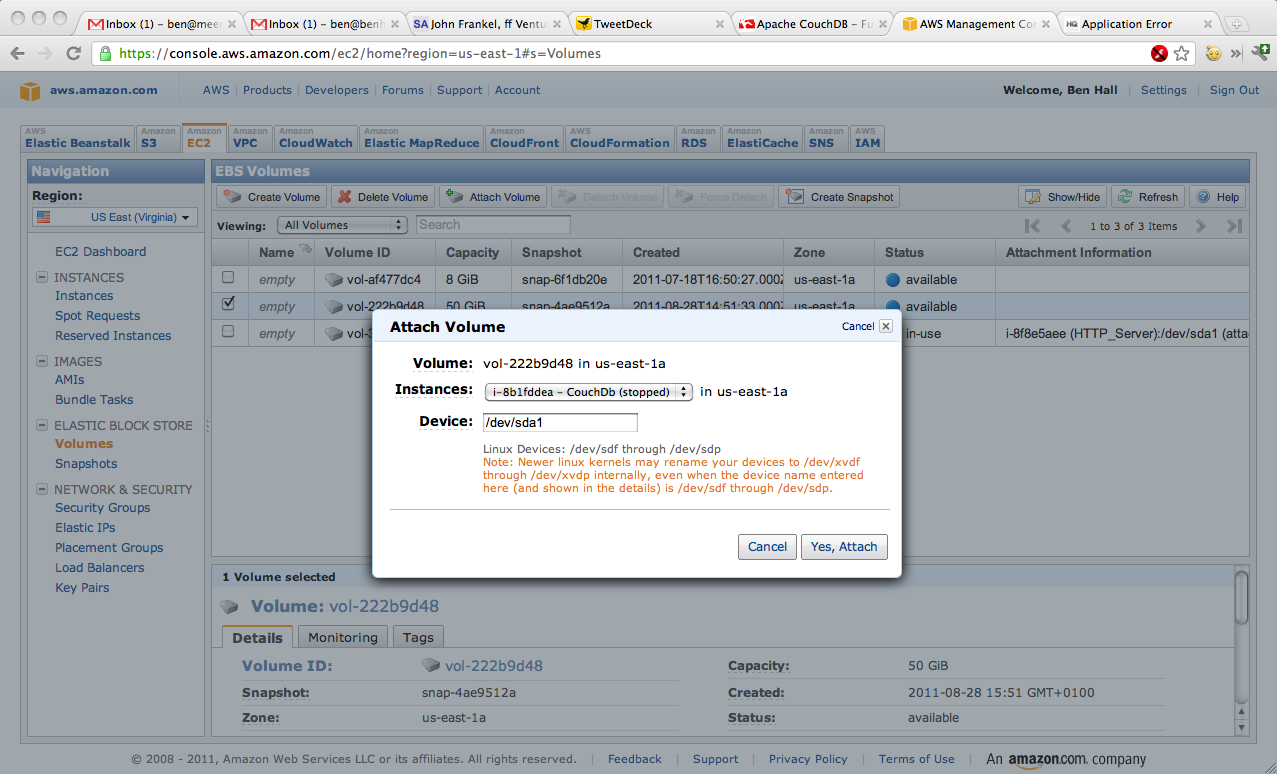
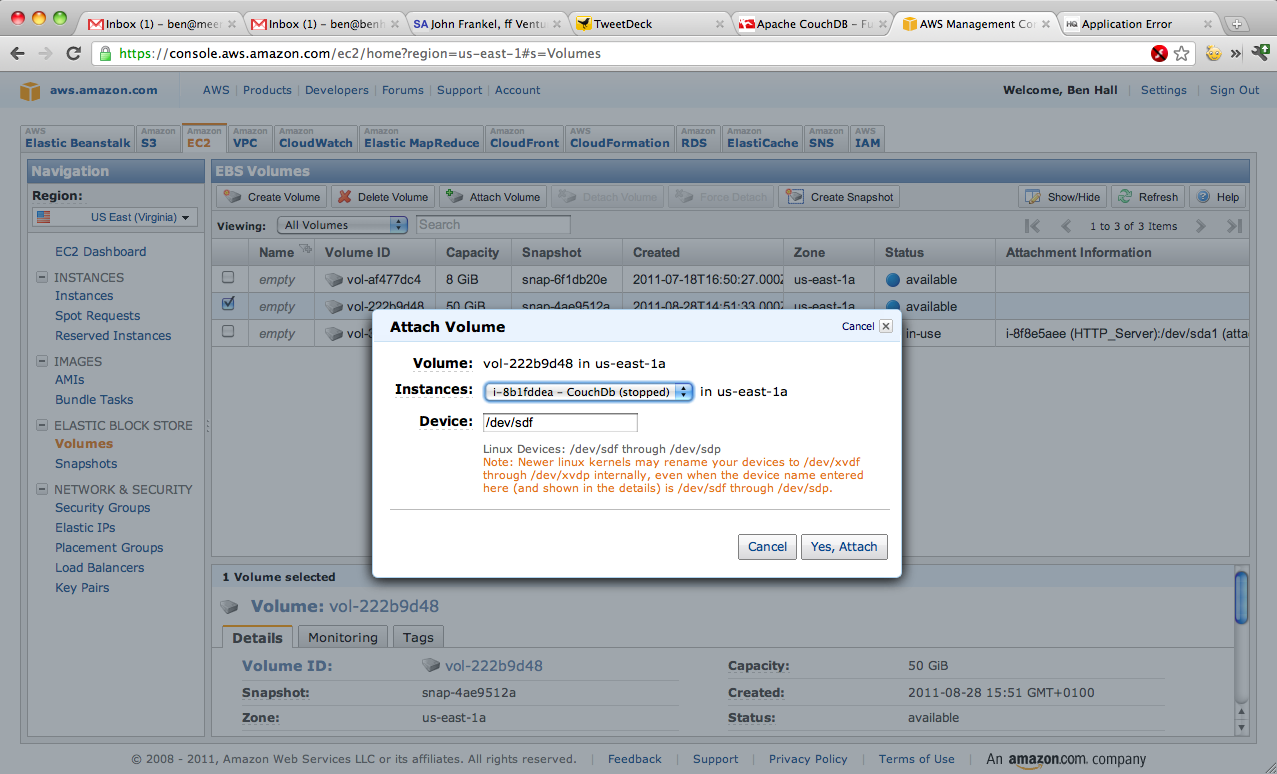
First, you need to find the instanceId for the machine you want to upgrade. The command “ec2-describe-instances” will list your running instances, with the instanceId being the number starting with a i-, for example “i-0000000”.
To make the change, you need to stop the machine using “ec2-stop-instances i-0000000”
ec2-modify-instance-attribute –instance-type m1.small i-0000000
INSTANCE i-8b1fddea running stopping
Client.IncorrectInstanceState: The instance ‘i-8b1fddea’ is not in the ‘stopped’ state.
instanceType i-8b1fddea m1.small
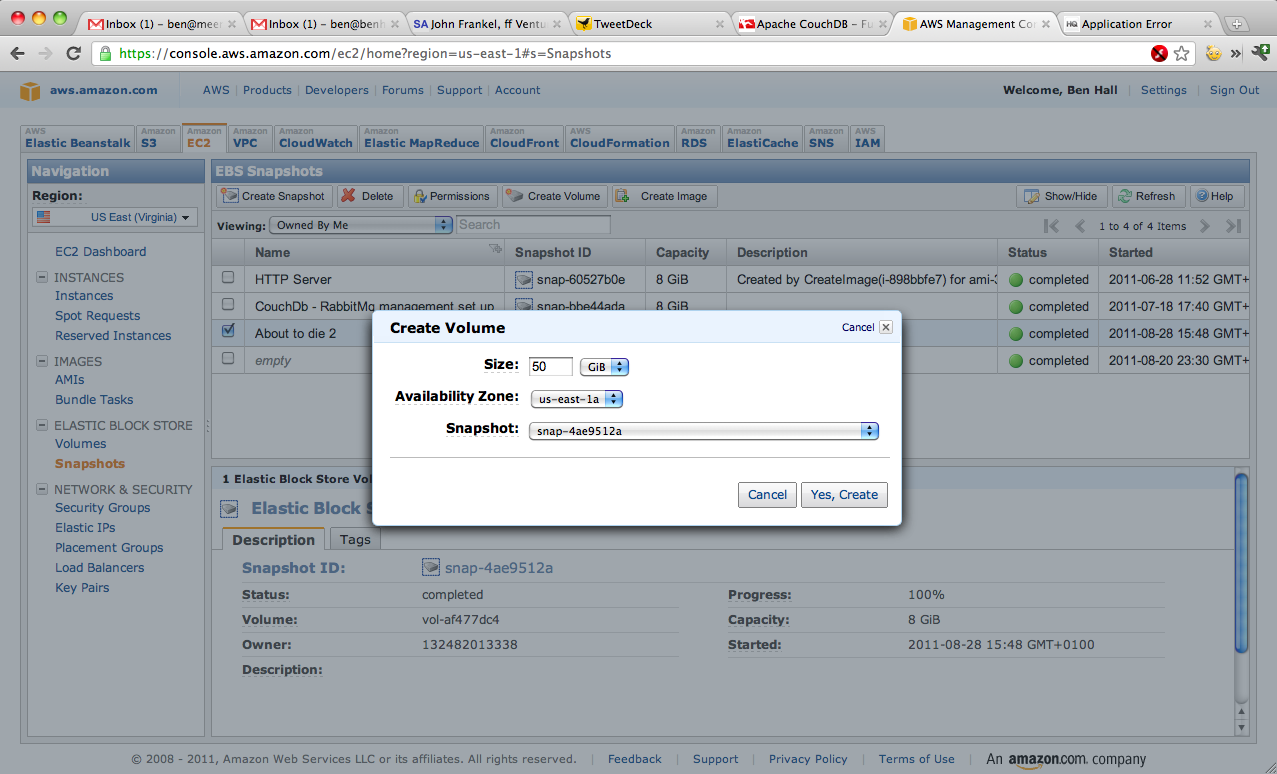
ec2-create-snapshot vol-af477dc4 –description “Moved to small 20/Aug/2011”
SNAPSHOT snap-020cce62 vol-af477dc4 pending 2011-08-20T22:30:05+0000 132482013338 8 Moved to small 20/Aug/2011
ec2-start-instances i-0000000