Partition Tables is a feature of SQL Server 2005 which allows you to separate your data into blocks (partitions) of data to improve performance and manageability as each partition can be stored in its own filegroup, which in turn can be on a separate disk array. In this post, I will cover how to partition your table, the table will contain a series of orders which I want to partition based on their order date.
The first thing I want to do is create a database.
CREATE DATABASE PartitionTest
GO
USE PartitionTest
GO
Next, I want to create a table which will contain all of my ‘orders’.
CREATE TABLE Orders (ID INT NOT NULL, OrderDate DATETIME NOT NULL)
Next, I got SQL Data Generator to generate me 10 million ‘Orders’ for the table. This gave me a large number of dates between 01/01/1953 and 30/12/2010 (values I had set) – so a nice big table which really needs to be partitioned. With that in place, we can create our partition.
First, we need to create a partition function, give it a name and the data type we are partitioning based on – in this case DateTime. We need say RANGE LEFT (anything on the left hand side goes into the partition), we then list the series of values we want to split the data based on. In this case, anything below 31/12/1950 goes into partition 1, between 1/1/1951 and 31/12/1960 into partition 2 etc
CREATE PARTITION FUNCTION OrderDateRangePFN(datetime)
AS
RANGE LEFT FOR VALUES (‘19501231 23:59:59.997’, –YYYYMMDD
‘19601231 23:59:59.997’,
‘19701231 23:59:59.997’,
‘19801231 23:59:59.997’,
‘19901231 23:59:59.997’,
‘20101231 23:59:59.997’,
‘20201231 23:59:59.997’)
At this point, we create a partition schema. In this case, I’m using saying all the partitions should be stored in the primary filegroup, however this is where we would allocate the partitions to separate filegroups.
CREATE PARTITION SCHEME OrderDateRangeScheme AS
PARTITION OrderDateRangePFN
ALL TO ([PRIMARY])
At this point, we have a table with 10 millions rows, a partition function and a partition schema. However, nothing links the partition to the table. What we need to do is create a new Primary Key which we can set the partition schema on. If you have any existing keys, they will need to be dropped and re-created with the partition schema included.
ALTER TABLE Orders
ADD CONSTRAINT OrdersPK
PRIMARY KEY CLUSTERED (OrderDate, ID)
ON OrderDateRangeScheme(OrderDate)
GO
If the table wasn’t already created, we could include the partition schema in the create table script.
CREATE TABLE Orders (ID int, OrderDate DATETIME) ON OrderDateRangeScheme(OrderDate)
GO
In the above function, the year 2000 partition was missing. If we wanted to include this we would alter the function and include a split range
ALTER PARTITION FUNCTION OrderDateRangePFN () split RANGE (‘20001231 23:59:59.997’)
After executing all of this, your table will successfully be partitioned. To verify the details of the partition, there are a few queries we can execute.
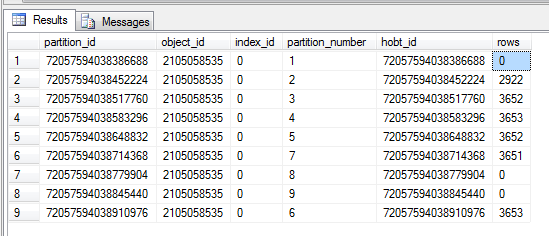
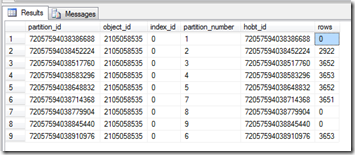
The system view partitons contains all of the information, we can query this to return all the partition information for a table.
SELECT * FROM sys.partitions
WHERE OBJECT_ID = OBJECT_ID(‘Orders’)
This returns the partition number and how many rows are in each partition. This is useful for identifying if your partitions are split correctly or if one partition needs to be split down more.
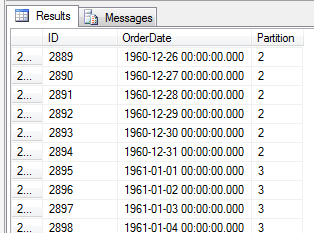
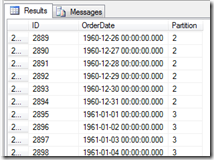
The other way is to use a $Partition, this gives the partition number for the row of data. This allows you to see what data is in what partiton
SELECT *, $Partition.OrderDateRangePFN(OrderDate) AS [Partition] FROM [Orders] ORDER BY [Partition]
More information visit http://www.simple-talk.com/sql/sql-server-2005/partitioned-tables-in-sql-server-2005/