Below are the slides and video of my “Running Docker in Development & Production” talk presented at NDC Oslo 2015.
Video
Running Docker and Containers in Development and Production – Ben Hall
Below are the slides and video of my “Running Docker in Development & Production” talk presented at NDC Oslo 2015.
Running Docker and Containers in Development and Production – Ben Hall
Git is now a key component of building software. While the basics are relatively simple to learn, the more advanced aspects can be difficult to pickup. The problem with learning Git, as with many technologies, is configuring a realistic scenario in order to start learning. If you’re using Git by yourself then it’s difficult to understand how to handle merge conflicts. Areas like Rebase and Cherry Picking are useful but just reading the man page doesn’t express why or when you would use them.
Many great resources already exist to help you learn Git but I find the best way for me to learn is to be hands-on and with examples to guide me. This is where Scrapbook comes in.
Scrapbook is a new interactive learning platform for developers. While many platforms aim to teach people the foundations of programming, very few support existing developers in keeping them up-to-date with the latest technologies and boost their experience.
The first course on Scrapbook focuses on Git and covers the common scenarios encountered. By combining a step-by-step tutorial explaining what’s happening along with a configured environment you can start learning instantly without having to download or config anything.
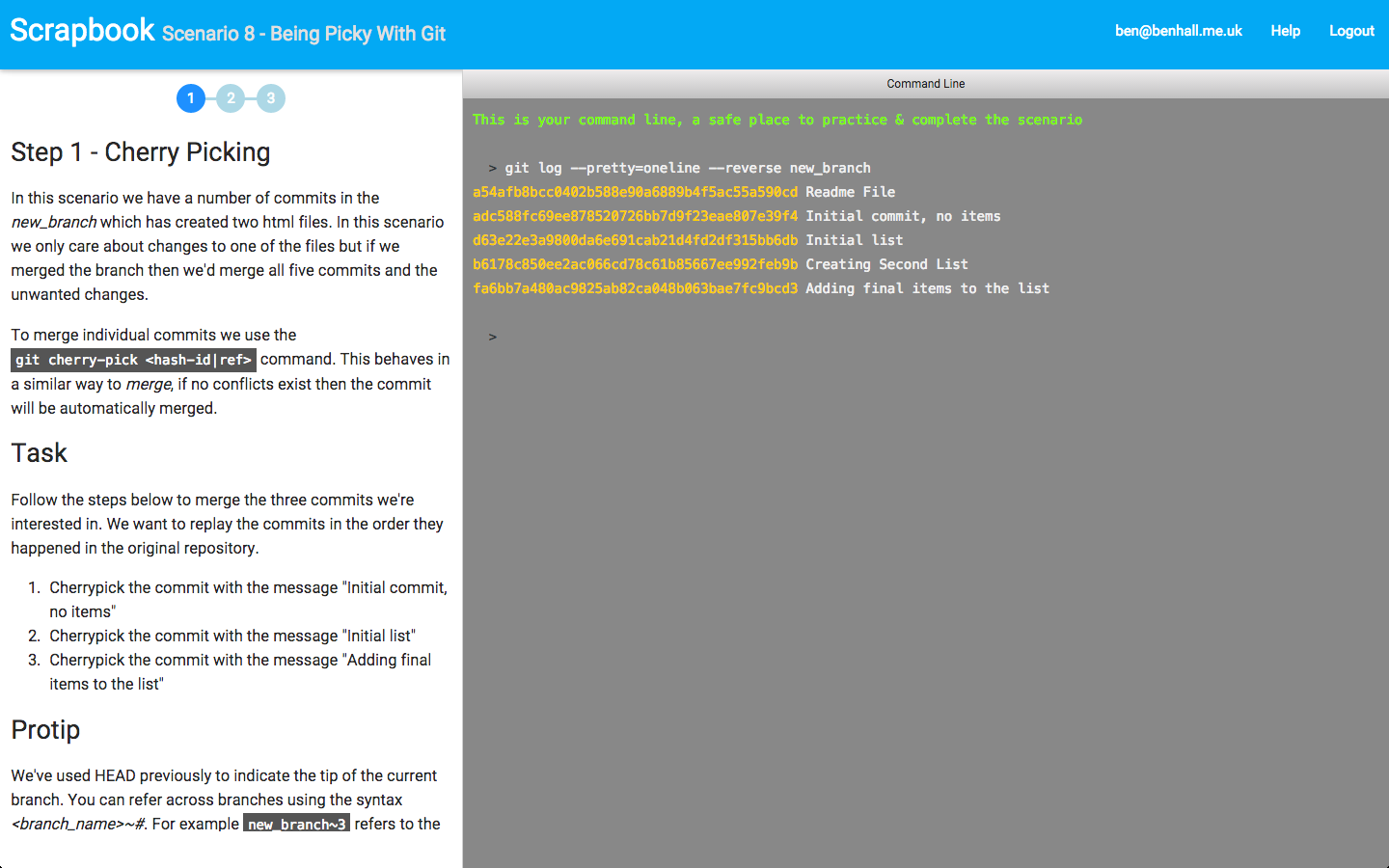
Currently in beta and for a limited time the course is available for free. Sign up at http://app.joinscrapbook.com/courses/git/
We’d love you’re feedback on the course, the platform and the topics you would like to see in future. You can reach us via [email protected]
Slides from a recent presentation I gave on Running Docker in Development and Production.
Keep an eye out for additional presentations, content and training material on Docker.
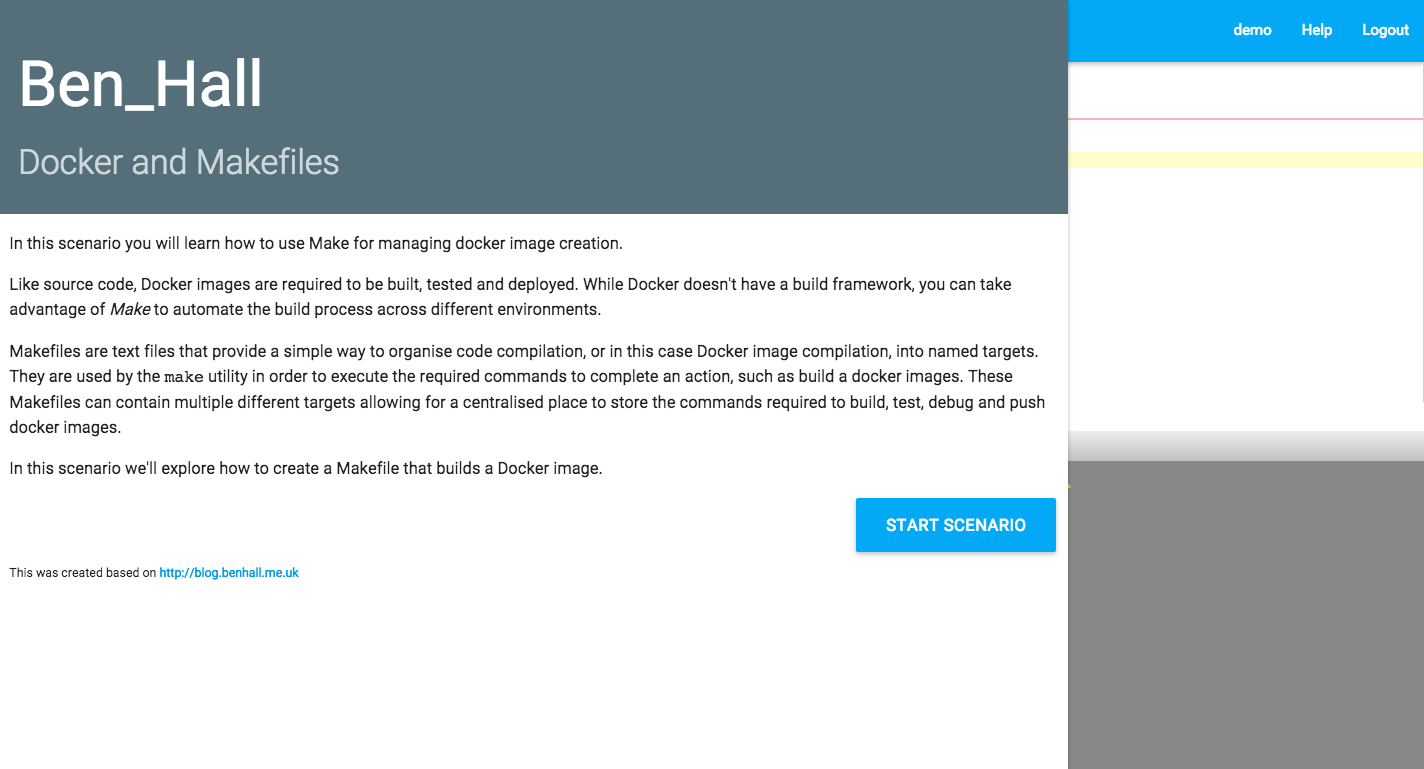
Like source code, Docker images are required to be built, tested and deployed before they can become containers.
While Docker doesn’t have a build framework, you can take advantage of Make to automate the build process across different environments. By using Make you can have a consistent and shared approach to managing your Docker images without the overhead of using task managers such as gulp.
To execute commands you need a Makefile. The Makefile contains a list of targets that define the commands and arguments required to be executed in order for a particular task to be performed, such as building a Docker image.
The contents of a Makefile might look like this:
build:
docker build -t benhall/docker-make-example .With this in your project’s root directory, executing the command `make build` will now build the container image.
A Makefile can define multiple targets reflecting different actions. The template below demonstrates a useful Makefile template covering the common scenario’s for managing Docker images.
NAME = benhall/docker-make-demo
default: build
build:
docker build -t $(NAME) .
push:
docker push $(NAME)
debug:
docker run --rm -it $(NAME) /bin/bash
run:
docker run --rm $(NAME)
release: build pushLearn Docker and Makefiles via Scrapbook, an Interactive Learning Environment.
An interesting Hacker News post this morning mentioning that certain Cloudflare IP addresses might be on the Sky Broadband blocklist. As a user of Cloudflare this is extremely concerning as end users will start to see random behaviour of my websites.
As more ISPs start to block wide reaching services without consideration for other websites then this will only happen more frequently.
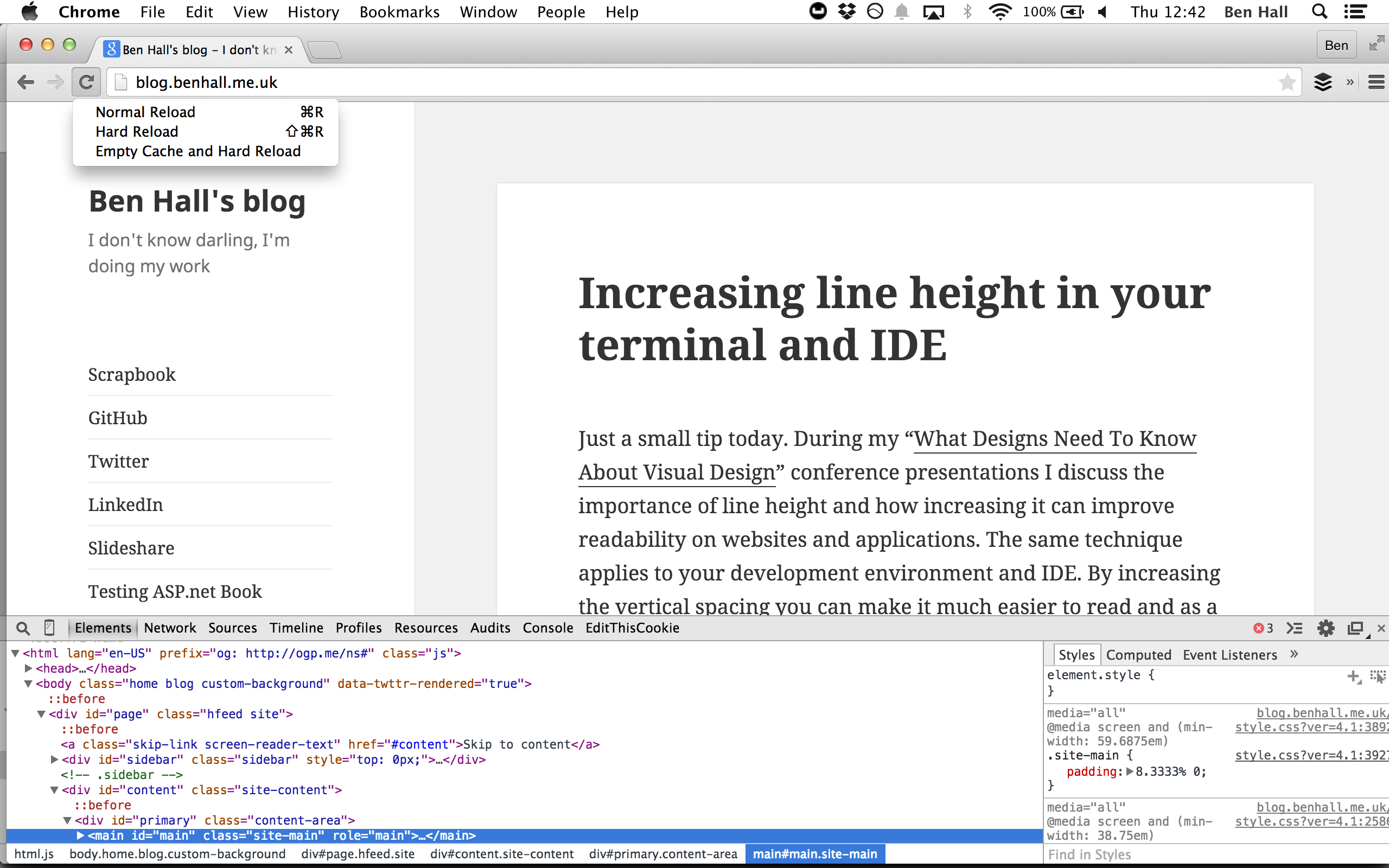
Working with JavaScript and CSS daily is a joy, until it’s not and then it’s a nightmare. Browser caching is just one of the aspects that can make working with these technologies a little more difficult.
To make life easier, with the Dev Tools open in Chrome, click and hold the Reload menu item. A new dropdown will appear allowing you to Empty Cache and Hard Reload the page.
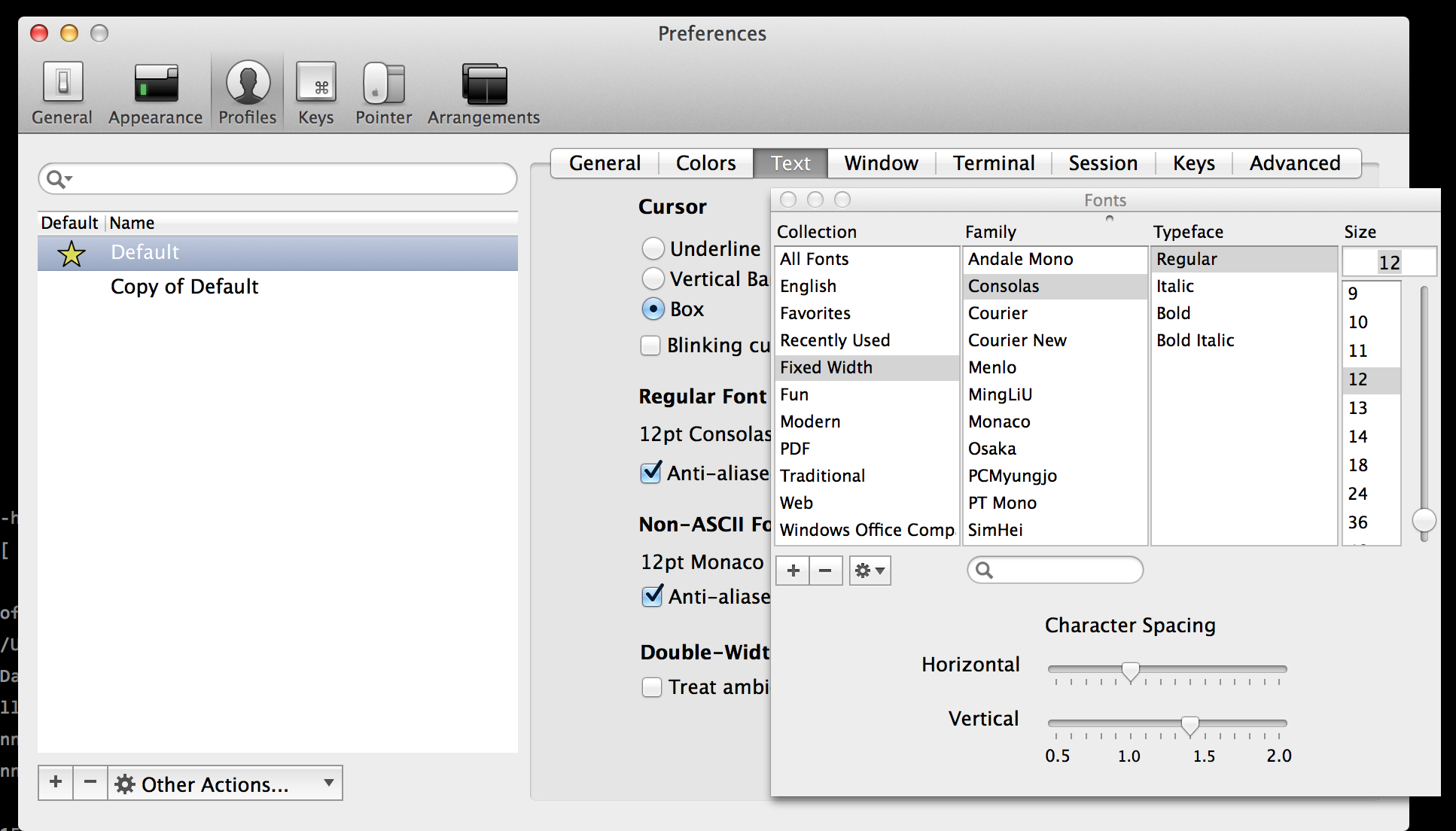
Just a small tip today. During my “What Designs Need To Know About Visual Design” conference presentations I discuss the importance of line height and how increasing it can improve readability on websites and applications. The same technique applies to your development environment and IDE. By increasing the vertical spacing you can make it much easier to read and as a result shouldn’t require as much effort meaning you’re slightly less drained at the end of the day.
Within iTerm you can set the line height in the text preferences.
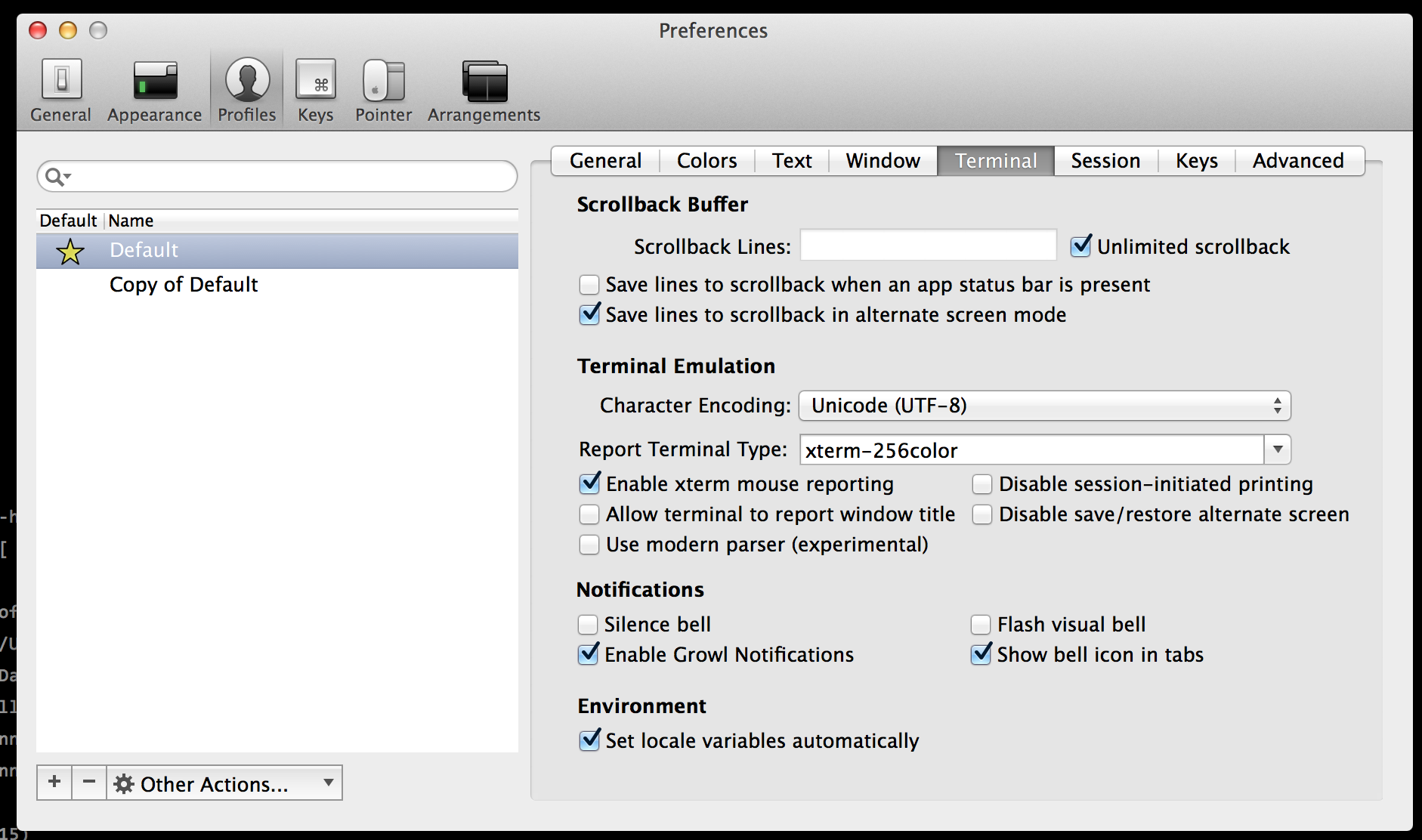
The default profile within iTerm limits how many lines of output it caches and allows you to scroll back. When debugging a large amount or a long running terminal session this can become frustrating.
To enable unlimited scrollback simply go into the preferences, on the terminal tab you’ll find the “Unlimited scrollback” option. Tick and you’ll be able to see everything and not just the last 10000 lines in future.
Ngrok offers the ability to “I want to securely expose a local web server to the internet and capture all traffic for detailed inspection and replay.”
While playing with RStudio, a R IDE available inside a browser, what I actually wanted was ngrok to “securely expose a local web server running inside a container to the internet”
Turns out it is very easy. Let’s assume we have RStudio running via b2d on 8787.
To proxy to a port on our local machine we’d use:
$ ngrok 8787
Sadly this will fail as our b2d container is not running on 127.0.0.1
The way around it is to define the boot2docker hostname/IP address
$ ngrok b2d:8787
You’ll get the output:
Forwarding http://47df0f.ngrok.com -> b2d:8787
All HTTP requests to the domain will now be forwarded to your container. Very nice!
For those wondering why I have a b2d hostname, I added it to my hosts file because typing is sometimes the bottleneck.
$ cat /private/etc/hosts 192.168.59.103 b2d

While having a cache can help WordPress scale you encounter one of the hardest computer science problems of cache invalidation. When a new post is published then the homepage cache needs to be broken in order to refresh.
When using Varnish there is a really nice wordpress plugin called Varnish Http Purge. Under the covers when a new post or comment is published it issues a HTTP PURGE request to break the cache.
Unfortunately if you have cloudflare in front of your domain then it will attempt to process the PURGE request and fail with a 403. After all you don’t want the entire world being able to break your cache.
$ curl -XPURGE http://blog.benhall.me.uk
<html>
<head><title>403 Forbidden</title></head>
<body bgcolor="white">
<center><h1>403 Forbidden</h1></center>
<hr><center>cloudflare-nginx</center>
</body>
</html>My solution was to add a /etc/hosts entry for the domain on my local machine to point to the local IP address. When a HTTP request is issue to the domain from my web server then it skips cloudflare and goes straight to the Varnish instance, allowing the cache to be broken and solving the problem.