While the usage of Docker in production has mixed reactions, it’s usage for development and continuous integration is overwhelming.
Having used Docker in development for the past two years my usage patterns has changed. To begin with I used Docker as an accessible way to have local instances of Redis or Postgres running on OSX or Windows. More recently I’ve been using it to run various language tools and environments instead of using version managers.
Version managers used to be a necessity. When maintaining more than a few applications, you would end up requiring more than one version of Ruby, Node, Java, etc running on your machine. Version managers made it simple to switch versions, but also become another thing to install and manage. When working with other developers, the problem of pinning to a particular version became harder to maintain. New starters would start with the latest version without realizing team’s current version.
Fast-forward to Docker and we can now have a practical and accessible approach for process isolation. I apply the same method to the various programming language runtimes. For example, when testing upgrading to Node v4 or Node v5 I used a Docker container to experiment without changing my environment.
This method became even more necessary with Golang. Different open source projects built against different versions. I found staying synced to the correct version with the correct configuration and path settings to be non-trivial. Version managers helped maintain my system but didn’t help me sync with others.
With Docker and a simple Bash command, you can launch the correct versions, with the directories mapped to particular locations and interact with it as if it was on your local machine. For example, the following command launches a Golang environment for my application.
docker run -it --rm
-w /go/src/github.com/$(NAME)
-v $(pwd)/vendor/github.com/:/go/src/github.com/
-v $(pwd):/go/src/github.com/$(NAME)
golang:1.4.2
The command maps the current directory to /go/src/github.com/. I store all the vendor dependencies in /vendor/ in source control, but remap them to a different location for the Golang runtime. I can run the same commands such as go get or go build as if Golang was on my host. When I upgrade, I just delete the docker image and pull down the correct version. Nothing else hanging around on my host.
Mark Rendle recently used this same approach for running the latest version of DotNet on different Linux distros called DockNet. By moving the runtime into a container, you have greater control, flexibility and shareability.
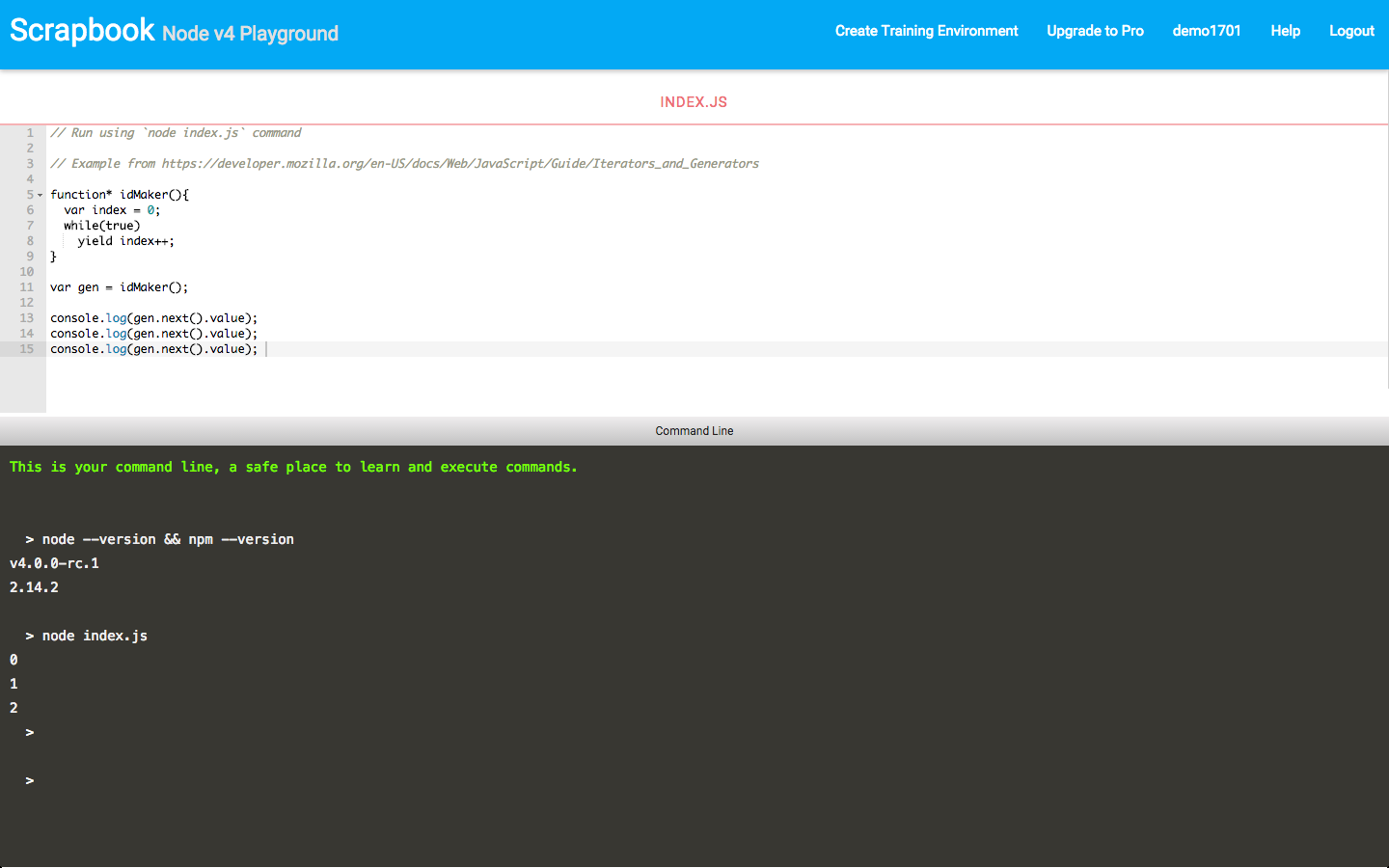
Want to see it in action? Load the Katacoda environment below. The editor has a simple “Hello World” application. Clicking Run will launch you into a Docker container, where you can run node, start the process and access the service like usual.
var requestListener = function (req, res) {
res.writeHead(200);
res.end(“Hello, World!”);
}
var server = http.createServer(requestListener);
server.listen(3000, function() { console.log(“Listening on port 3000”)});